Unifying Robustness and Fidelity:
Authors: Anonymous
Abstract: Enhancing speech signals in adverse acoustic environments is a long-standing challenge in speech processing. Existing deep learning based enhancement methods struggle with removing background noise and reverberation in real-world challenging scenarios. To address this challenge, we propose a novel approach that uses a pre-trained speech codec to synthesize clean speech given degraded inputs. In addition, we conduct a comprehensive comparison with two other pipelines: mapping-based and vocoder-based speech enhancement. Experimental results on both simulated and recorded datasets demonstrate the effectiveness and robustness of our proposed method. We observe generative methods show stronger robustness against degradation compared with conventional mapping-based speech enhancement. In particular, by leveraging the codec, we achieve improved audio quality with reduced background noise, and reverberation.
Architectures of the proposed vocoder and codec approaches
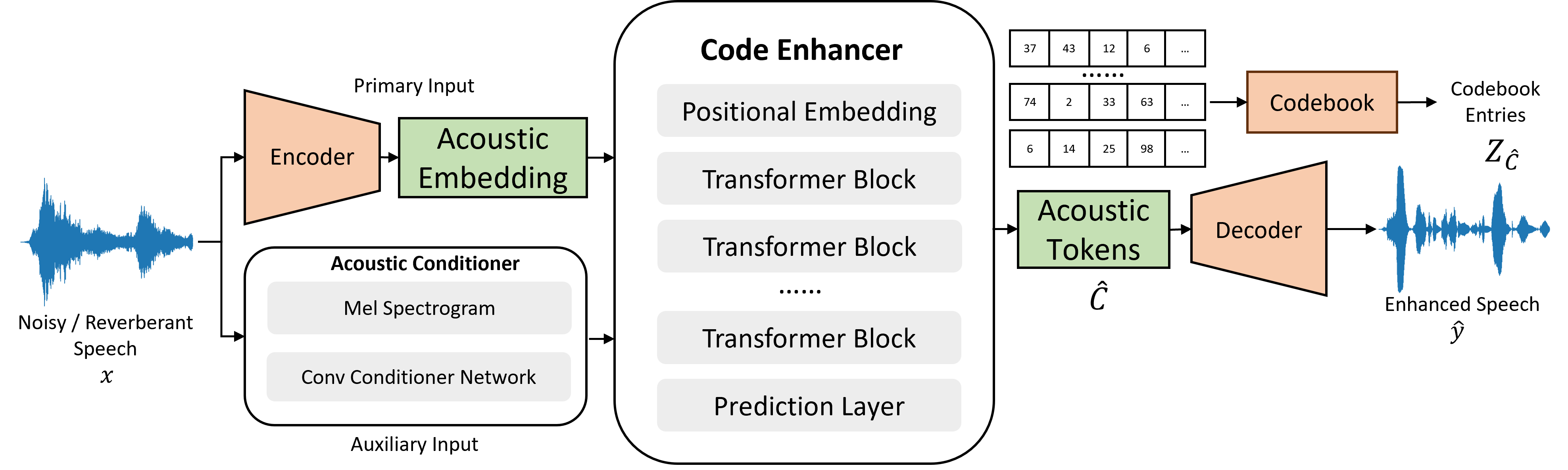
Fig. 1: the architecture for the proposed codec pipeline. |
|

Fig. 2: the architecture for the vocoder-based pipeline. |

Fig.3: the architecture for the mapping-based pipeline. |
Results
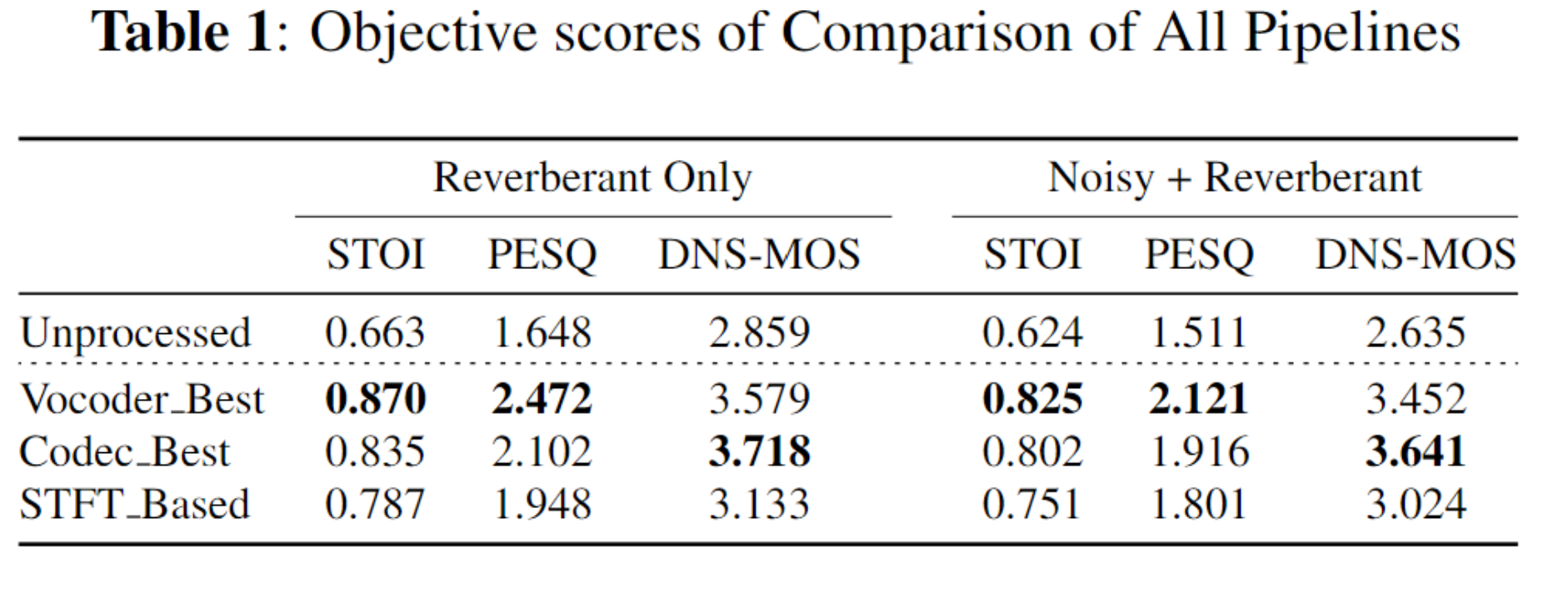 Objective scores of All Pipelines for Comparison. |
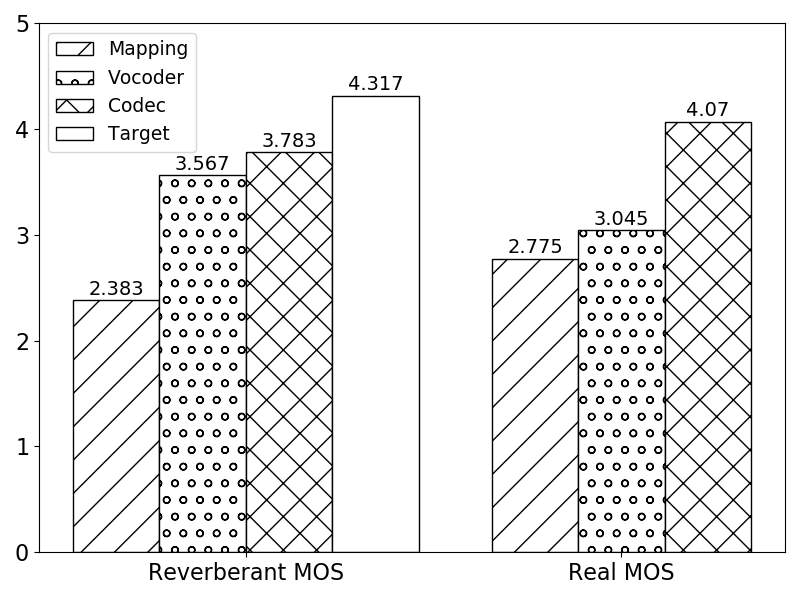 Diagrams of MOS for both synthetic and realistic samples. |
Audio Demos
We provide audio demos for both simulated data and real-world recordings:
I. Reverberant Samples
| ID | Unprocessed | STFT-based | Vocoder-based | Codec-based | Ground Truth |
|---|---|---|---|---|---|
| A | |||||
| B | |||||
| C | |||||
| D |
II. Real-world Recordings Samples
| ID | Unprocessed | STFT-based | Vocoder-based | Codec-based |
|---|---|---|---|---|
| E | ||||
| F | ||||
| G | ||||
| H |